

Agent & Harness & Micro-Orchestrator, Oh My!
An introduction to agentic orchestrator wizardry and how to build your own.


It’s been a while since I last posted on here, but for good reason, as I’ve spent the past few years crossing off a bucket list item of writing an O’Reilly Book on the topic of Data Contracts. The book was published in November 2025, so what have I been doing for the past five months?
Spending every minute I could spare using Claude Code until my needs eventually outgrew it (more on that soon).
This article ended up being quite long, so it’s broken up into three parts:
Part I: Emerging Agentic Patterns - An Abridged History
A quick overview of the past three years of our industry’s transition to AI, and defining AI agents, agentic harnesses, and agentic orchestrators.
Part II: A Case For Micro-Orchestrators
Highlighting a gap I see in the market between robust orchestrator frameworks (e.g., Langchain) and the ever-popular rise of agentic “skills” via markdown files.
Part III: Building Your Own Micro-Orchestrators
A case study on a micro-orchestrator I built and published as an open-source package on PyPi, the hard lessons learned, and a deep dive into why I think the event sourcing data architecture pattern is ideal for complex agentic workflows.
All throughout, I’ve linked articles and resources that have had a major impact on my learning in this space and that I believe will be an excellent reference for you as well.
Finally, I want to give a huge thank you to the following people who provided feedback on early drafts of this post: Skylar Payne, Aaron Pitt, and Nathan Suberi.
If you are a techie like me, then I imagine the past five months have been similarly intense. While I’ve been using AI-assisted coding tools since the copy-paste-from-chat-window days, last November felt like a major inflection point where AI went from “Nice auto-complete!” to “This just wrote the entire script better than me in one minute…”
It’s jarring at first, as you question the value you now bring to your career, so you dig deeper to understand. This is also why you see so many people building intensely right now. It hit me the most when my friends outside the intense startup grind started sharing the crazy hours that matched my 80+ hours a week. While I can’t predict the future, going deep on these tools has only shown me how important software and data foundations are. We are not going anywhere, but our work in software and data is drastically changing.
This article details the key areas I think data practitioners should focus on to evolve toward agentic systems and proposes the micro-orchestrator pattern as an abstraction that I believe will prove useful as agentic workflows grow. In addition, I provide a real-world example of a micro-orchestrator through an open-source Python package I created and break down key considerations for building your own!
If you want to learn more about how I specifically use AI agents for spec-driven development, then check out this interview I did with the Motherduck team: Specs Over Vibes: Consistent AI Results
Part I: Emerging Agentic Patterns - An Abridged History
I first heard about AI Agents in early 2023 when I interviewed Jazmia Henry about her work as an AI researcher—back then, she was on the Microsoft team that ultimately became part of OpenAI. It’s wild how accurate her quote is today:
So that's the biggest challenge [of AI agents is] having a goal and that goal being as close to the actual problem, especially if you’re gonna deploy it. And then the second thing is finding that darn data and making it as close as possible to the actual world so your agents actually learn something of value and not fail.”
Unbeknownst to me, this single interview altered my course in data and made me hyper-aware of the data industry's changing landscape. Back then, the wider data industry was still obsessed with OpenAI’s ChatGPT. She was simply talking about the future we are experiencing today. Since this interview, there have been three specific architecture patterns that have emerged to make these powerful AI models useful beyond chat windows:
The AI agents themselves, and specifically the ability for LLMs to use tools for long-horizon task completion.
Agentic harnesses, such as Claude Code, enabled LLMs to manage memory, use tools, and, overall, create the winning UX for agentic coding.
The emerging category of agentic orchestrators for reliably completing repeated workflows at scale.
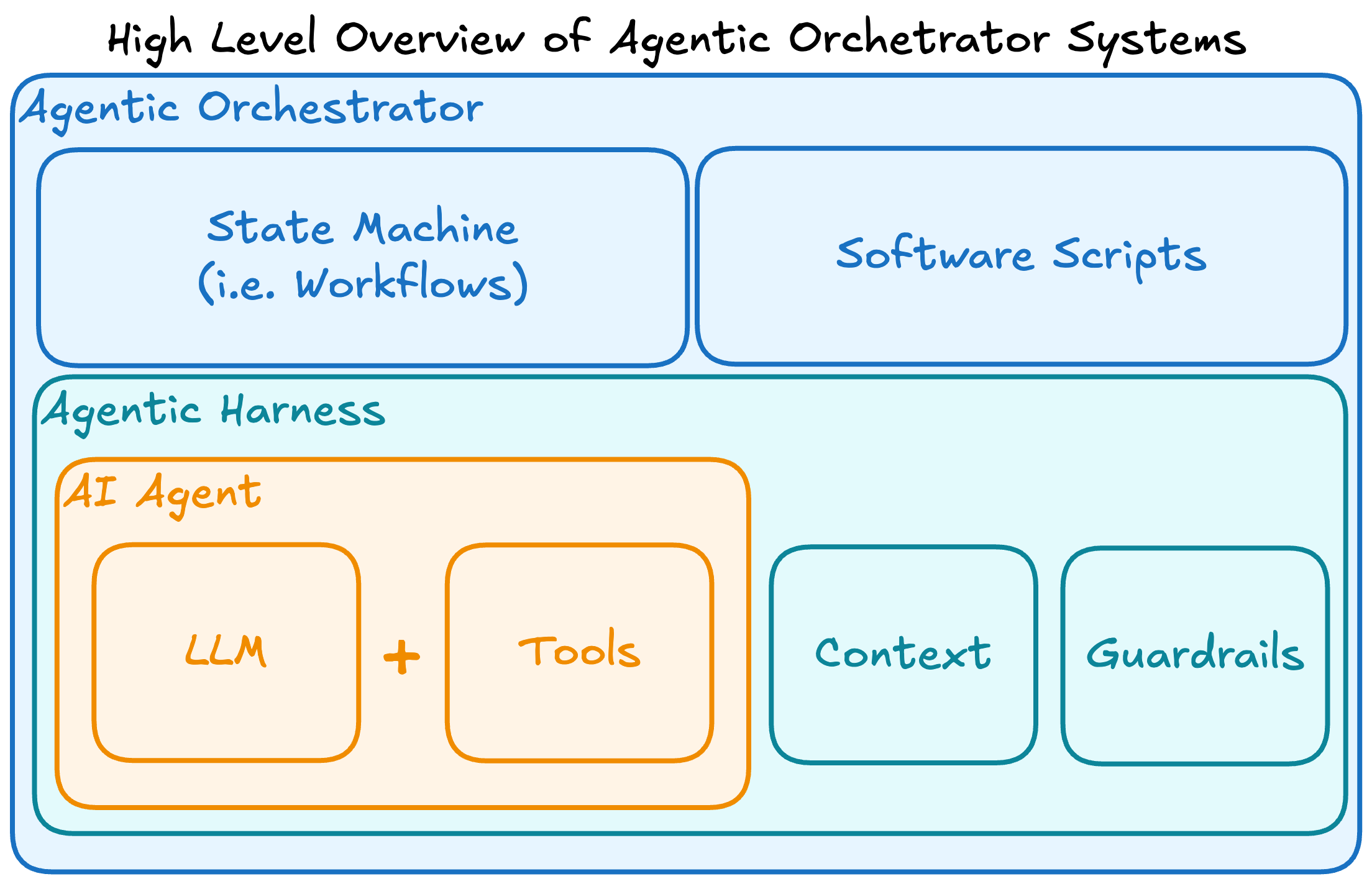
These three changes are the inflection point that moved agents from a cool experiment to fundamentally reshaping how software is built and every assumption around it.
AI Agents
The second article that shifted my data career was Chip Huyen’s Agents blog, which was adapted from her O’Reilly book chapter on the topic. Specifically, she provided this insight:
A system doesn’t need access to external tools to be an agent. However, without external tools, the agent’s capabilities would be limited. By itself, a model can typically perform one action—an LLM can generate text and an image generator can generate images. External tools make an agent vastly more capable.
At the time, most AI engineers and researchers I knew advised moving away from chat windows and using LLMs via their APIs for greater control. Claude Code merely made best practices accessible to the wider developer community.
I highly recommend reading Chip’s article, as it covers AI Agents better than I could in this short paragraph. But our main takeaway is that we must think about AI Agents as “LLMs + External Tools” as the core primative for agentic harnesses and orchestrators.
Agentic Harnesses
As the utility for LLMs grew, so did our demand for long-running tasks that were not tethered to a chat window. Thus, to keep our robot friends running continuously, the industry has focused on leveraging agentic loops (i.e., Observe → Plan → Generate → Verify) via what are now called harnesses. Yet, spend any amount of time with AI agents, and you quickly learn that they are eager little geniuses that will do exactly what you say— regardless of whether what you said is your actual intent. Their capacity for synthesizing knowledge is only exceeded by their capacity to wreak havoc if you give it too much room (i.e., the siren call of --dangerously-skip-permissions).

While many like to point to the latest frontier models and their ability to wreck the curve on Humanity’s Last Exam, the sudden jump in agent utility points back to the harnesses themselves. Specifically, the harness provides human operators with a mental buffer against the deluge of decisions an agent must make and enables self-checking agentic loops that request a decision only after a goal has been met.
Agentic Orchestrators
So what’s the next obvious step for AI agents if you are a token-maxxing degen like myself? Orchestrators! My first introduction to this world came from using Claude’s Agentic Teams feature and reading Steve Yegge’s article, Welcome to Gas Town, where the popular social media image of Stages of Dev Evolution stems from:


Core to this process of orchestrating agents is optimizing their context windows to constrained subtasks within a larger workflow. If you have used the Plan feature of Claude Code, you have seen this in action, where it takes a request, determines the goals for completion, and then uses sub-agents to do the work in parallel. Orchestrators take this approach and then ask how much we can scale it horizontally while still maintaining reliable outputs.
I believe orchestrators will represent a meaningful amount of development work as agents become increasingly embedded in our workflows. Primarily because much of the conversation of value and revenue is moving towards an emphasis on “outcomes completed” instead of “work completed.” Thus, domain-specific yet repeatable workflows that were often not targets for automation—due to significant context-specific edge cases—are now becoming possible for organizations. This is also why you see so many non-technical subject matter experts (SME) driving insane value with vibe coding.
The problem is that this demographic of Claude Code users isn't exposed to what’s actually needed to move from a prototype they use only themselves to actual production software businesses depend on. The latter is why developers are safe in this new AI world for now, but this doesn’t discredit the fact that these domain-specific vibe coders are identifying valuable agentic use cases. Similar to developers supporting data science teams by turning their Jupyter Notebook prototypes into production software, the same is now happening for non-technical SMEs.
Part II: A Case For Micro-Orchestrators
To be clear, there are already agentic orchestration frameworks, such as LangChain, but they are heavy and akin to a company adopting tooling like Airflow. This is why you have seen the proliferation of agentic skills, which provide a lightweight alternative that enables repeated workflows by simply writing or importing Markdown files with plain English instructions.
Markdown Development Is Not Enough
Despite how powerful they are, agentic skills have an Achilles' heel: they are unreliable without constant maintenance effort or guardrails. Your AI agent first needs to know the skill exists, understand what context to trigger the skill, and even with that context, the agent may still not trigger the skill. Even if you put in the work to achieve reliable skill utilization, the constant changes to the underlying frontier models’ weights and system prompts can cause skills to drift in unexpected ways.
I highly recommend this research paper, "How Well Do Agentic Skills Work in the Wild: Benchmarking LLM Skill Usage in Realistic Settings," which delves into the fragility of skills (and their promise) in greater depth.
With generalizable orchestration frameworks being too heavy and agentic skills being too fragile, there is a need for what I’m calling micro-orchestrators.
Abstractions Move From Software to Taste
As I mentioned before, much of the value in agentic AI deployments lies with subject-matter experts who are closest to the most valuable problems the business is solving. Furthermore, if it were just a technical problem, these workflows would already have been automated—they are not, due to context-specific edge cases that only SMEs can handle. AI agents have changed this assumption, as their core strength lies in retrieving specific information, synthesizing patterns within their active context window, and then taking action based on inputs and/or responses.
For example, in a previous data science role, I developed data quality algorithms for unstructured electronic health record data and thus needed to collaborate with subject-matter experts. Specifically, physicians with sub-specialties (e.g., ophthalmology) on our staff would validate my assumptions and ensure clinical accuracy. Now imagine physicians who are no longer encumbered by a lack of technical skills and can build tools that map directly to the problems they see in their own clinics.
Coupled with plummeting software implementation costs, businesses are rushing to deploy their own AI agents to handle work directly, rather than relying on users to log in to a SaaS tool. Thus, the bottleneck now becomes taste, as OpenAI’s co-founder succinctly puts it:

Now, some may be saying, “Well, isn’t that exactly what the job has always been?” To which I respond, yes, but now the work is compressed in ways I argue the wider industry is currently struggling to handle (no one is being spared; Examples: Amazon, GitHub, Meta, Anthropic, etc.). Having your end user be both humans and agents is completely new for most people and companies.
Another way to put it, the same way you offload development to open-source packages is now being expanded to offloading taste. We have moved from “now I don’t have to build it” to “now I don’t have to detail my thinking for agents.”
Thus, offloading cognitive demands for taste in the context of workflow completion is the ultimate goal of micro-orchestrators.
Part III: Building Your Own Micro-Orchestrators
I have yapped A LOT, but one of the main lessons I’ve learned in this new AI world is that talk is cheap… ideas need to be accompanied with something built. So I created this fun project to bring this idea to life (and pay homage to my favorite video game). To my shock, there have been over 3.5k downloads on PyPi.
Case Study - Petri
Specifically, when I work with agents, I spend considerable time curating context (internal documents, prompts, sources of information, etc.). Thus, I aimed to automate that process and then open-sourced it as Petri.
You provide a claim, such as “open-source AI models will reach frontier lab levels in a year,” and the orchestrator will break it down into first principles, find recent and relevant citations online, evaluate the quality of the citations, and then build an argument for or against the claim with various nuances. What’s wild is that I also got this to fully work locally with OpenCode and Qwen 3.6-35B-A3B-GGUF on my MacBook Pro (M1 Max, 64GB)!
You can download it directly via uv pip install petri-grow or by prompting the following into your agentic harness of choice:
“Help me onboard onto this Python package: https://github.com/onthemarkdata/petri”
You can also just watch a fun demo video here… yes, Petri has video game background music.
While this is great and all for my own workflows, what about your specific work? The next few sections will break down key considerations for building your own micro-orchestrator.
State Machines - The Backbone of Agentic Workflows
Earlier, I stated that agentic skills are powerful but fragile. I learned this firsthand while building Petri, where the first iteration was handled fully through agentic skill markdown files. While it looked cool having my terminal buzz with agents, the massive burn of paid tokens left a mess of “research thoughts” that ultimately didn’t follow the complex workflow. Specifically, the agents were more eager to complete the task than to complete it correctly, and optimized for the quickest, ideal success path.
My second iteration still leveraged all agentic skills but added human review checks at each decision point for me to verify, with agents creating GitHub issues that I would comment on for feedback. This actually worked and validated that it was possible, but this approach was not feasible beyond this iteration. In particular, I spent over 10 hours reviewing and commenting on 100+ AI-generated GitHub issues. I learned A LOT about how agents operate across various logic scenarios, but I wouldn’t want to do it again. It became clear that I need to spend more time determining exactly where an agent should be used and optimizing my workflow for deterministic mechanical processes whenever possible.
Thus, I asked myself how I could establish a workflow that followed a deterministic path while allowing non-deterministic outcomes. I quickly realized I had covered these exact scenarios in my grad school public health modeling classes, specifically that I could use state machines to represent the execution steps of probabilistic events. What resulted was the following state machine for Petri (please note you can see a detailed version in the docs):

I cannot emphasize enough how big this is. If we can create a state machine that an agent follows, then we can also predict how changes to this state machine will result in changes in agentic behaviors and outputs, given that it’s all math and probabilities. In public health, this is essentially how epidemiologists can perform sensitivity analyses of various disease-spread scenarios.
Why Agentic Workflows are a Distributed Computing Problem
Another surprising learning from building Petri was how much agentic engineering is essentially data engineering. Again, we want to scale this work horizontally, so instead of having 30+ developers on a platform, I need to build for the same scenario across all the agents I oversee. Thus, I reframed the requirements as a data engineering problem rather than an AI one:
You break a complex workflow into individual tasks to keep the context window small and contained to only the task that needs to be completed.
These tasks have components that are sequential or can be done concurrently, but we need to assume that ALL happen independently.
Given that each agent and task are independent, the deployment of an agent (not its runtime) in a long-running workflow must be idempotent (deployment, not output).
Given that any independent task can fail at any time (hooray, non-determinism), the workflow must gracefully handle failures and retry the task.
Each state of the task, whether completed or failed, needs to be added to an append-only log that is edited programmatically (not by agents).
This is essentially a data pipeline, where the “data” we are moving and preparing for our end-user (i.e., the AI agent) is context. Even better, despite AI agents being bleeding-edge, we can leverage tried-and-true data architecture patterns to provide “shortcuts” for improving their reliability and utility. In particular, distributed computing problems map extremely well to the orchestration of AI agents, which also points to the use of event-driven architectures.
Event Sourcing and Immutable Logs
Writing the Data Contract book made me quite familiar with event sourcing, as its section required the most research and stress, given my primary experience in batch systems. While most people point to Martin Kleppmann’s book, Designing Data-Intensive Applications, as the quintessential book for our field… I posit that his magnum opus (at least to me) is his Orielly Report published a year before, Making Sense of Stream Processing.
Note: If you don’t have an O’Reilly Subscription, Kleppmann published a free blog post with essentially the same information.
One of his main arguments for adopting event sourcing was the use of an immutable log that all systems read from to maintain the proper state for their respective tasks. In particular, each unique system has its own specific business context and use case, which may overlap but ultimately serve different purposes, even though they are derived from the same data. The figures below illustrate how that maps extremely well to agent orchestration. In particular, since AI agents are stateless, we can optimize their memory and context window by feeding the latest event from our event stream as input to their next task and relevant triggers.
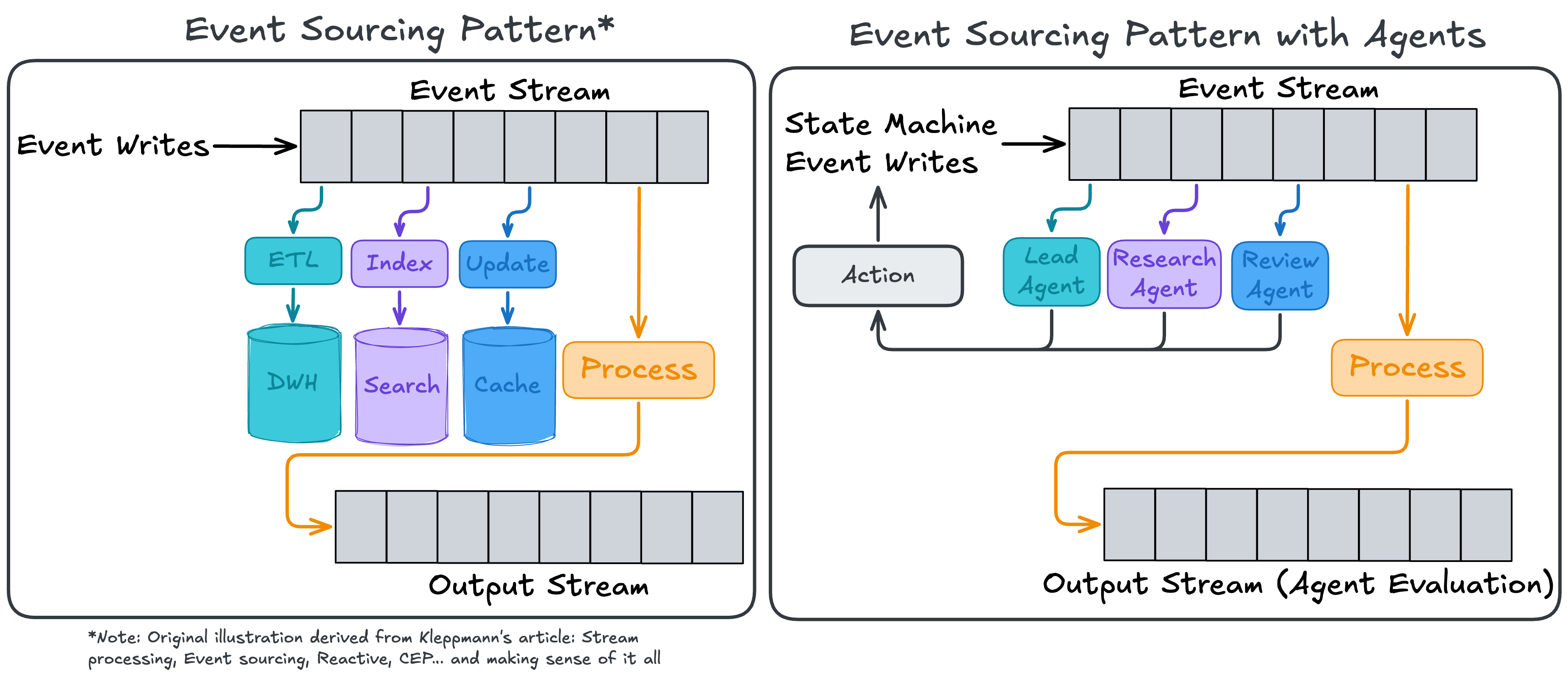
For example, in Petri, the Lead Agent reads the event stream to determine the last completed task. If the log shows that the Research Agent wrote a failed task (e.g., didn’t have the correct permission to view a website), the Lead Agent will flag a GitHub issue (or even in the main harness chat window) that a permission is needed. Furthermore, all other concurrent agents will recognize, from the event stream's immutable log, that this task is in the stalled stage of the state machine and proceed to other tasks until the queue is complete or all remaining tasks are stalled. This is powerful because now we don’t need to waste context on ensuring the agent is aware of an unrelated task— instead, it sees the current state, its options given the task, and a source of truth it can always reference to ensure it’s reaching its proper goal.
In other words, the immutable log from event sourcing enables full audits of agents (when tied to observability) and allows an agent to retain context and replay a workflow if a failure occurs and a new independent agent needs to be re-run. By applying data architecture best practices, we unlocked significant reliability and memory capacity for our agentic workflow.
Agentic Hierarchies for Context Management
One area of agent orchestrators that is both fascinating and where I think Petri has a lot of room for experimentation is how you organize agents and the boundaries of their communication with each other and or with human operators. This is also where I think many executives’ heads are when they think about how AI transforms work. For example, Jack Dorsey (CEO of Block) and Roelof Botha wrote an exceptional article, "From Hierarchy to Intelligence," drawing parallels between AI agents in the workforce and shifts in communication across human organizations throughout history. In addition, some of my former Humu colleagues are now leading rigorous applied research efforts on the topic at Atlassian’s Teamwork Lab.
For Petri, I opted for a three-level hierarchy, as illustrated in the figure below, composed of a main agentic harness agent, a lead agent for a given queued task, and under the lead agent, a set of specialized subagents for each stage in the state machine.
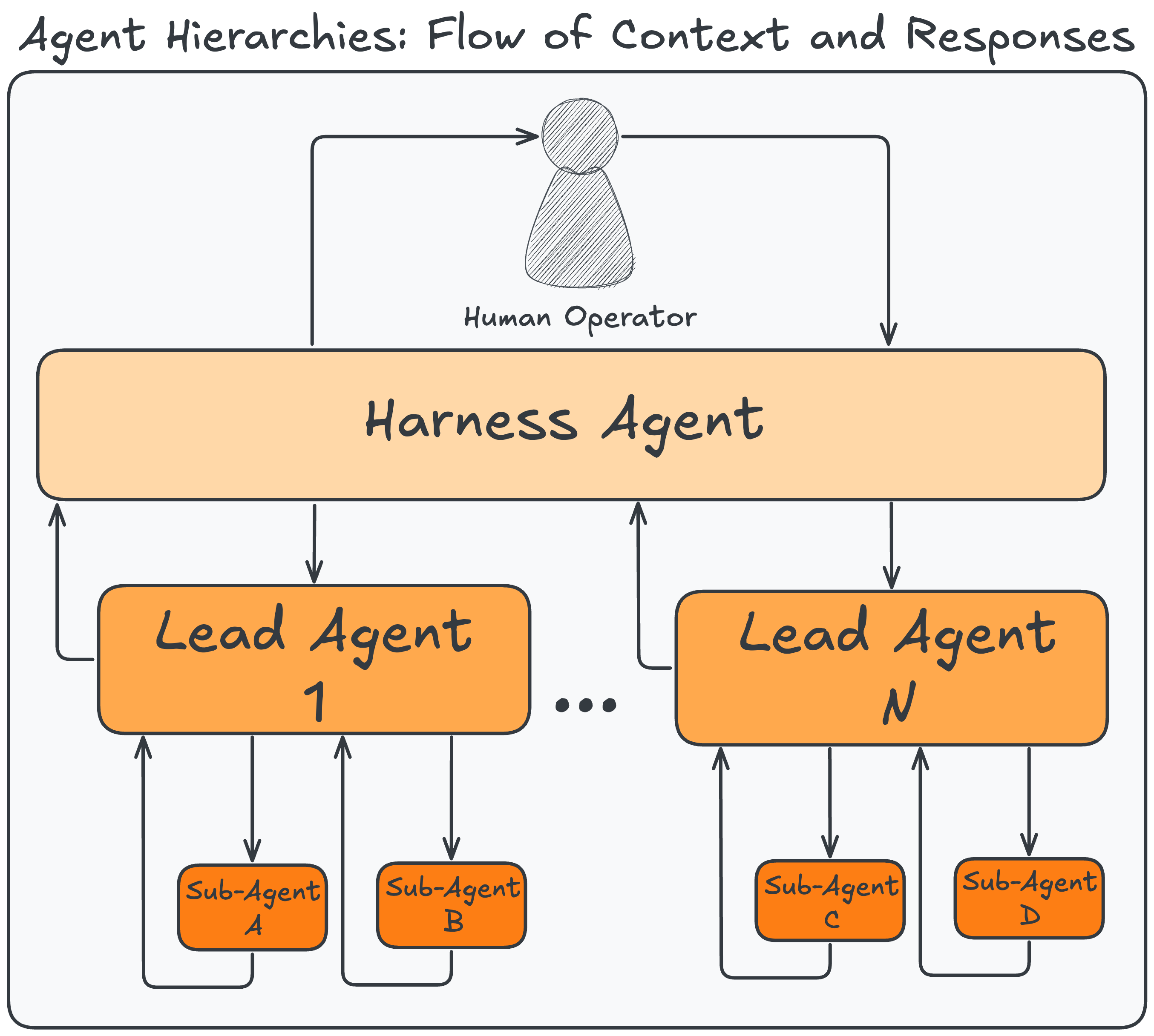
Furthermore, only the main Harness Agent is aware of all tasks and can dispatch Lead Agents for each queued task, with the only provided context being the task itself. The Lead Agent has three key roles:
Dispatch specialized sub-agents based on the state machine triggers.
Synthesize the sub-agents' outputs and make a decision.
Given that decision and context, trigger the event logging script.
This clear separation of information flow results in agentic workflows that run for hours, rarely have a context window exceeding 100k tokens (i.e., no context rot or compactions), and ensure multiple context perspectives are presented for synthesis. The latter point is a little less obvious, but most people are familiar with how syncopathic LLMs are and their affinity for recency bias (e.g., going overly positive or negative, based on the most recent prompt). By leaning into that constraint, you can have an ensemble of agents given different angles (e.g., for Petri, making a case for and against a piece of evidence), and then have the Lead Agent synthesize all perspectives into a balanced response.
As I said earlier, there is ample room here to optimize your micro-orchestrator and showcase your “taste” for these workflows. For example, in Petri, many of the improvements I’m working on center on the logic of how agents break down claims into specific units of logic and research questions—a challenging but fun problem.
The Data of Agentic Harnesses
Finally, no improvements to your micro-orchestrator can occur if you don’t actually capture its logs and, more importantly, read the trajectories of the agents (i.e., the turn-by-turn inputs and outputs of an LLM within a harness and its accompanying metadata). Thankfully, many agentic harnesses come with pre-built logging that is emitted as streamed JSON (e.g., for Claude Code CLI, it’s --claude -p "query" --output-format json-stream). This is a great starting point, as you can locate the local files and read them for yourself.
You can take this a step further by passing these logs into an open-source agentic observability tool such as Langfuse or Signoz, and extending them to the orchestrator itself via the OpenTelemetry (OTel) specification. What’s most exciting is that the wider industry is standardizing on OTel, making it easy to integrate agent tracing and observability across multiple tools. I have implemented this in other private projects, and it’s downright terrifying when you actually dig into the trajectories and see how the agents’ output resulted from not properly following a set of instructions, and instead creating a mock of what was expected. This was the moment I knew observability was a necessity for agentic workflows, and not a nice-to-have.
What’s Next for Scaling DataOps
I hope these lessons learned from building Petri can give you a jump-start in exploring how to build your own micro-orchestrator using agents. With the book finally done and having more free time to build again, I am excited to get back to writing long-form content on this newsletter. I have some awesome content planned as I dive further into AI agents and explore how to scale their infrastructure. Specifically, I decided to go deeper into this space and purchased an RTX Pro 6000 Blackwell GPU workstation to start building with fully open-source AI models and fine-tuning them for my specific use cases. Just like this article, as I build and learn, I’ll be sure to share my lessons with you all here!